As an application grows, so does the load on its database. A database that can’t keep up with demand will lead to slow response times, timeouts, and outages. Scaling a database involves making changes to handle increased workloads while maintaining performance and availability.
In this article, we’ll explore common database scaling techniques, steps to scale out a relational database, and key considerations when planning a database scaling strategy.
Database scaling refers to methods of increasing a database’s capacity and processing power to handle more data and workload.
Data is the new oil, and analytics is the combustion engine.
📀
A scalable database allows you to handle massive volumes of data, reduce latency, improve performance, and ensure seamless data accessibility. It enables businesses to make informed decisions, foster innovation, and maintain a competitive edge.
There are two main approaches to scaling a database:
A) ⬆️ Vertical Scaling
Vertical scaling involves increasing the processing power and memory capacity of a single database server. For example, you could upgrade to a server with a more powerful CPU, add more RAM, or increase storage space.
The main advantage of vertical scaling is simplicity – you scale by making hardware improvements to a single server. However, there are limits to how much you can vertically scale. At a certain point, you reach hardware limitations and diminishing returns.
B) ➡️ Horizontal Scaling
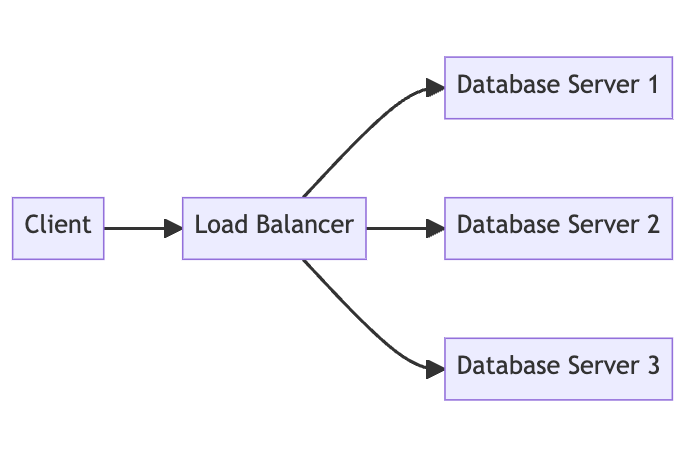
Horizontal scaling means distributing the database workload across multiple servers. Examples include database replication, sharding, clustering, and other distributed database architectures.
Horizontal scaling allows almost unlimited expansion since you can add more servers to handle increased loads. It also provides redundancy and failover capabilities. But scaling out adds complexity in terms of database administration, query optimization, and maintaining data consistency across servers.
| Scaling Method | Pros | Cons |
|---|---|---|
| Vertical Scaling | – Simple to implement – Single server is easier to maintain – No coding changes needed – Improves performance up to a point |
– Hardware limits on scale – Single point of failure – More expensive hardware needed – Diminishing returns |
| Horizontal Scaling | – Limitless scale-out capacity – Built-in redundancy – Cost-effective commodity hardware – Improves performance across multiple servers |
– Complexity of distributed system – Query routing and optimization – Data consistency challenges – More servers to manage |
Bare Metal vs Virtual Machines vs Containers: The Differences
When deploying a modern application stack, how do we decide which one to use? Bare Metal, VMs or Containers?

#1. Monitor and Analyze Current Usage
Begin by monitoring key metrics like CPU utilization, memory and storage usage, concurrent connections, cache hit rate, and query response times. Analyze usage trends to forecast when you’ll need to scale.
#2. Identify Performance Bottlenecks
Profile database workloads to find bottlenecks holding back performance. Slow queries, small connection pools, and low memory or I/O bandwidth are common limiting factors.
#3. Choose the Right Scaling Method
Decide whether to scale vertically or horizontally based on the bottlenecks, data volumes, and application architecture. A hybrid approach often works best.
#4. Implement Scaling Changes
Add servers, increase hardware specs, adjust database configuration, shard or replicate data, etc. Make changes during maintenance windows to minimize downtime.
#5. Test and Optimize
Load test scaled infrastructure, tune databases, optimize queries, and make configuration tweaks. Iterate until the system handles projected workloads comfortably.
9 Best Practices for Developing Microservices
The Best 9 practices for developing microservices. From separate data storage to code maturity and container deployment in software development.

#1. Hardware Limitations
There are limits to how much you can vertically scale a single database server. At some point, you’ll need to scale horizontally.
#2. Data Volume Changes
If data volumes are growing rapidly, horizontal scaling approaches like sharding allow limitless expansion of storage and I/O.
#3. Query Patterns
Read-heavy workloads can often be scaled by adding read replicas and caching layers. Queries hitting different tables may require sharding.
#4. Costs
Balance hardware and licensing costs against performance needs. Scaling out adds servers you must purchase, configure and maintain.
DevOps vs GitOps: Streamlining Development and Deployment
DevOps & GitOps both aim to enhance software delivery but how they differ in their methodologies and underlying principles?

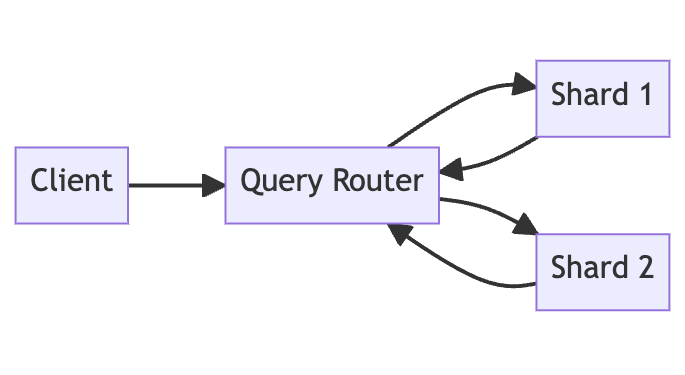
#1. Database Sharding
Database sharding is a scaling technique that partitions a large database into multiple smaller databases called shards. Sharding helps improve performance and availability for both reads and writes.

There are two main sharding approaches:
- Horizontal sharding splits a database table so that each shard contains unique rows of data. This distributes the data load across servers.
- Vertical sharding partitions a table into shards with unique columns and overlapping rows. This can optimize access for queries targeting particular columns.
✅
A key advantage of sharding is high availability – if one shard goes down, the rest of the database can still function. Outages are isolated to individual shards.
⚠️
Sharding introduces complexity in query routing, transaction management, and maintaining data consistency across the shards. There are also significant setup and maintenance costs with a sharded topology.
Sharding provides performance and availability that other methods can’t easily match for large datasets and workloads. But it is a critical technique for massive scale, even with the overhead required.
Read more about Database Sharding here.
What is Database Sharding?
Database sharding is a technique that splits a database into smaller shards to improve performance, scalability, and availability.

#2. Read Replication
Read replication uses a primary database for writes, while read-only replica databases handle queries. Distributing reads improves read speeds and overall performance.

✅
Putting read replicas in different regions can also optimize latency. However, there is a tradeoff – replicas may not have the most up-to-date data if writes on the primary have not propagated yet.
⚠️
While powerful, read replication adds complexity in managing replica propagation and lag.
But for large-scale read performance, read replication is an effective technique. It spreads load across servers to handle spikes in traffic and usage.
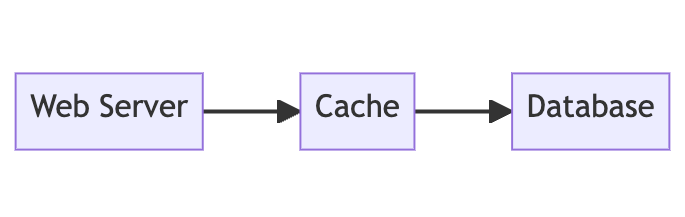
#3. Caching
Caching is a straightforward way to improve database performance for frequent queries. A caching layer reduces database load by returning frequently accessed data from fast in-memory caches instead of slower disk-based databases.

✅
Typically an app will have a few common queries that make up most of the database load. Rather than hitting the database over the network for these each time, the results can be cached in memory on the application server. When a cached query is made, the app will check the cache first and return the results from memory if available. This avoids repeated database roundtrips. The cache is populated on cache misses by fetching the data from the database and storing it.
Caching boosts speed by keeping commonly accessed data in low-latency memory instead of retrieving it from the database. It reduces the load on the database for unchanged data that is queried often. Just caching frequent queries can significantly improve throughput and response times.
Why Redis is So Fast It Will Blow Your Mind!
Find out Why Redis is so fast, even after over a decade since its creation.

#4. Move Session Data
Many apps store session IDs in cookies but keep the session data itself in a database table. This can burden the database with frequent reads and writes for session management.
✅
An option to reduce this load is using a fast in-memory cache like Redis or Memcached to store session data instead of the database. However, there is potential for data loss if the cache goes down.
➡️
Another approach is using JWT tokens to store the session details directly in the client-side cookie rather than the server-side. This avoids constant database hits for sessions. But JWT tokens have downsides like token size limits and security considerations.
⚠️
Potential downsides like data loss or token security need evaluation when choosing an approach.
Optimizing session storage with caching or client-side tokens can significantly lighten database load. Session data can be moved from the database to a cache. This avoids constant reads/writes to the database for session management.
#5. Database Indexes
Database indexing improves query performance by optimizing data lookup. Indexes allow the database to rapidly find and retrieve data from a table without scanning every row.

✅
When an index is created on a column, the database maintains a separate index data structure that keeps the column values ordered and searchable. This enables fast searching and sorting when queries filter or sort on that column.
The performance gains depend on the size of the table. For large tables with millions of rows, proper indexing makes a huge difference in optimizing data access.
#6. NoSQL Databases
NoSQL databases scale horizontally with built-in sharding. NoSQL databases distribute data across shards. Queries are routed to the appropriate shard.
✅
What Are the Different Types of Databases?
Learn about the various types of databases, including relational, NoSQL, and graph databases. Explore their features and benefits.

The flexibility and on-demand scalability of cloud platforms like Amazon Web Services (AWS), Google Cloud, and Microsoft Azure provide many advantages for scaling database performance. Rather than large upfront investments in on-premises infrastructure, the cloud allows starting with smaller database instances and seamlessly scaling up resources as needed to handle growing data volume and users.
#1. Scaling Databases in the Cloud
- Overview of the flexibility and scalability offered by cloud platforms like AWS, Google Cloud, and Azure.
- Ability to start with small resources and scale up seamlessly as needed.
- Avoid large upfront investments in on-premises infrastructure.
#2. Leverage Auto-Scaling
- Cloud databases like AWS Aurora can automatically scale compute and storage as needed.
- Set auto-scaling policies based on metrics like CPU utilization or throughput.
- Helps maintain performance during traffic spikes and as data grows.
#3. Managed Database Services
- Services like AWS RDS, and DynamoDB take care of scaling for you behind the scenes.
- Abstract away the operational burden of managing scaling.
- Built-in fault tolerance and high availability.
- Options for auto-scaling, read replicas, caching, etc.
#4. Database Clustering
- Tools like Amazon RDS allow running databases over clusters of EC2 instances.
- Horizontal scaling by adding read replicas, and partitioning data.
- AWS takes care of replicating data, failing over.
- Can implement shards on EC2 for scaling NoSQL databases.
#5. Choosing Cloud Database Model
- Relational databases like AWS RDS for transactions, and complex queries.
- DynamoDB for high scalability, and throughput of key-value data.
- ElasticSearch on EC2 for scalable full-text search.
- Graph databases like Neptune if relationships are critical.
#5. Testing and Migrate to Cloud
- Benchmark performance before migrating to the cloud.
- Test scaling capabilities under load before the full switch.
- Use replication and gradual cutover to migrate to cloud databases.
System Design vs Software Architecture : What You Need to Know
System design and software architecture are two sides of same coin, both integral to the process of creating a software system. But, they’re not the same thing.

#1. Monitoring and Alerting
- Set up monitoring tools to track performance metrics across all database instances. Monitor CPU, memory, I/O, network usage, query latency, errors etc.
- Configure alerting rules to notify if usage thresholds are crossed or problems occur. Quickly detect issues before they cause outages.
#2. Automated Failover
- Use auto-failover and redundancy features of databases like MySQL and PostgreSQL to reduce downtime. If the primary node fails, an automated secondary instance can take over.
#3. Backup and Recovery
- Implement regular backups and test restores across shards and replicas. Backups protect against data loss, and test restores verify recovery processes.
#4. Query Performance
- Continuously optimize slow queries by tuning and caching. Bad queries on one shard can bog down the overall database.
#5. Capacity Planning
- Plan ahead for expected growth in data volume and workload. Monitor usage trends and scale out shards/replicas proactively before hitting limits.
#6. Maintenance Windows
- Have downtime windows to perform database patching, upgrades, re-indexing, and other maintenance tasks.
With careful monitoring, redundancy, backups, and capacity planning, a scaled database topology can deliver high performance and availability. But maintenance tasks are critical to prevent issues down the road.
Conclusion
Scaling a database requires careful capacity planning, workload analysis, and performance benchmarking. Combining vertical scaling, horizontal scaling, caching, query optimizations, and database architecture changes allows for supporting high workloads. Monitor workloads closely, iterate and tune your scaled configuration, and plan maintenance windows to prevent outages. With the right database scaling strategy, you can build a data infrastructure that handles increasing demands smoothly.
What Makes Load Balancer vs. API Gateway Different and Use Cases ?
Discover the key distinctions between Load Balancer and API Gateway, along with their unique use cases like efficient traffic distribution & integration.

FAQs
What is the difference between scaling up and scaling out?
Scaling up (or vertical scaling) means increasing the resources of a single server. Scaling out (or horizontal scaling) means distributing load across multiple servers.
When is database sharding recommended?
Sharding helps when you have large volumes of data, high write throughput, or complex/long-running queries that can be isolated.
How can caching help scale databases?
Caching improves read performance by avoiding reading from disk. It reduces database load for frequently accessed unchanged data.
What are tips for testing scaled databases?
Load test with expected peak workloads, monitor performance metrics, check query response times, and iterate to resolve bottlenecks.
How can NoSQL databases help with scaling?
Many NoSQL databases have built-in horizontal scaling, replication, and sharding specifically designed for easier scaling.